Poor data quality is the evil that plagues marketing campaigns. In this article, Léonard shows you how to defeat this multi-headed hydra, launch and succeed in your Data Quality project.
The symptoms of evil
Maybe you’re already convinced that you should take care of data quality, maybe not. Some common symptoms that the evil beast has taken over your kingdom.
The word CRM integration makes you wake up at night
You don’t understand how it works, you feel like some fields are swapped, others are not. The same field appears several times in your Marketing Automation with different, almost similar names (for example the Country field) and you never know which one to use. When you pass the CRM manager in the hallways, you shave the walls
Your targeting never gives the expected results
Every time you prepare a targeting for a campaign and estimate that you have X number of people, you have half as many. After a little analysis, you realize that the fields are
- either empty because the data has been filled in another field,
- or they have been filled in incorrectly (UK instead of United Kingdom for example)
And you don’t have time to correct everything by hand.
You have no idea of the precise consents given by your prospects and customers
You have a general idea via this field, oh no, this one, or maybe this one if I cross-reference it with this campaign… But it’s difficult to have an immediate, reliable, precise idea.
You regularly receive insulting emails
From men you’ve called “Madam”. Or from customers to whom you have offered a prospect discount, and who discover the discount they were not entitled to as a customer. Or from people who have told you 15 times that they no longer want to be invited to your webinars. Your self-esteem is at an all-time low.
Your lead gen forms are long and convert poorly
Because you have little data on people, you ask for a lot of data… and prospects convert less because nobody likes long forms.
You refuse to measure the duplicate rate in your database to keep your sanity
This is your “dark room” that you refuse to enter. You know it’s there, and that a horrible truth is hiding inside… But sometimes it’s better to ignore the truth, to have the illusion of living happily. In short, the picture is not rosy, but you have finally decided to face it head on! Together we will defeat this multi-headed hydra, and I will show you how.
Sign up for the Data Quality program: 11 exclusive contents to understand the subject and know how to fight the hydra of bad data quality!
Prerequisite to your Data Quality project: Understanding the development of the Hydra, or the dynamics of poor data quality
It is important to have in mind how bad quality is born, propagates and settles in your systems in order to prepare your Data Quality project. We have prepared this Miro to help you see it more clearly, either in images or directly in Miro.
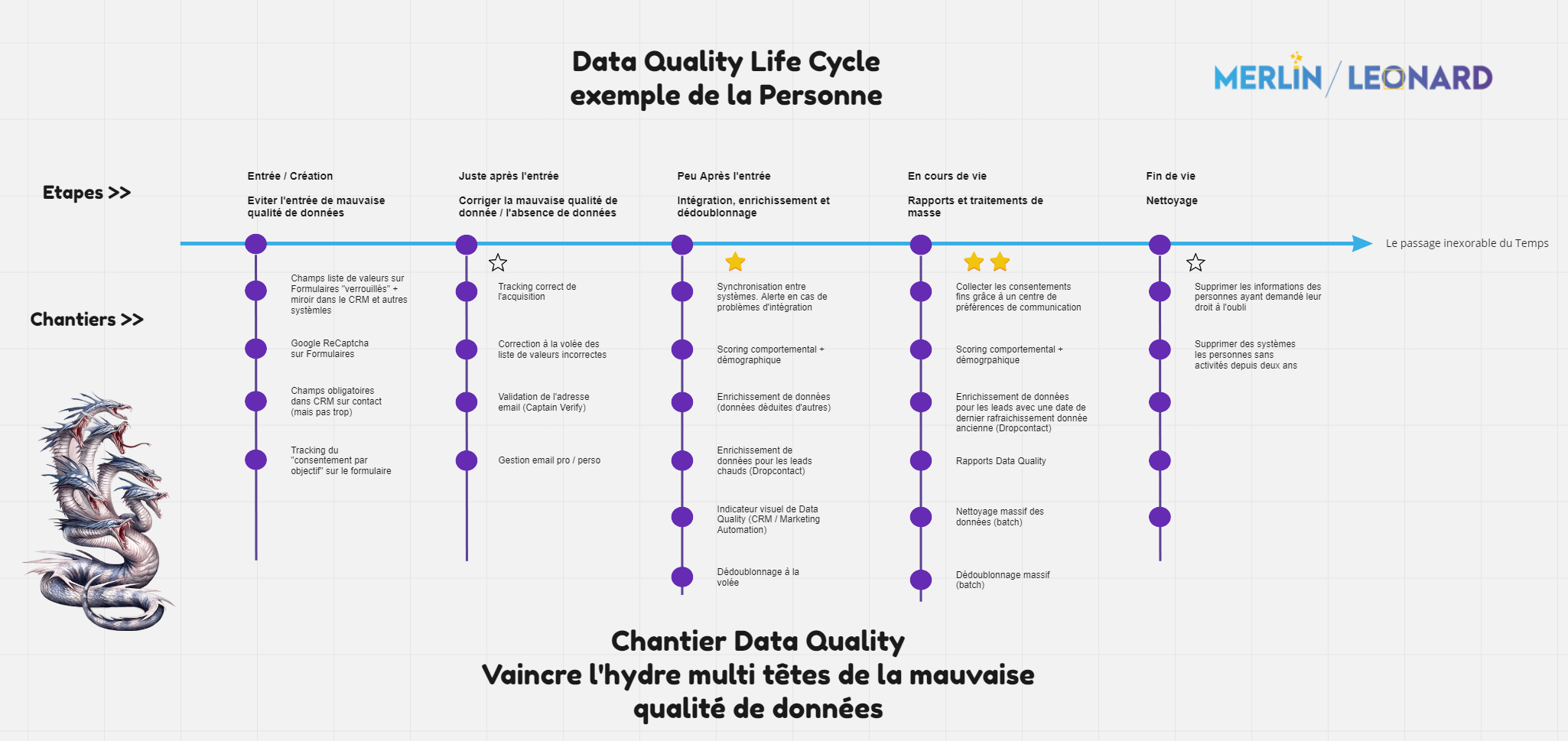
To deal with the subject properly and defeat each head of the hydra, it is necessary to understand the dynamics of Data Quality, which is a living matter. You will need to
- confront the demons of the past (clean up the existing bad quality),
- put on your most shining armor (avoid bringing in bad data quality)
- and fight evil as soon as it appears (correct on the fly).
Avoid bringing in evil
To defeat the Hydra’s heads, nothing is better than avoiding feeding the Beast. Various techniques are available to you to defeat the Evil at the source.
Secure your forms
Forms are a great source of poor quality, and at the same time, a great source of lead generation. The actions you can take to limit the entry of poor quality data. Be careful, this should not be done at the expense of the customer experience. The idea is to keep the form as short as possible to maximize conversion.
- use lists of values instead of text fields (for example for countries)
- avoid asking for data that you may have elsewhere. The title which can be deduced from the first name
- secure your forms with a Google Recaptcha or equivalent
- do not allow “personal” emails to be entered if you are in B2B. Provide an exception process for those who don’t have any other emails at that time)
- avoid asking for fields that you can deduce elsewhere (civility, decision level…). You want to keep your forms as short as possible, don’t ask for information you can get elsewhere
- offer a drop-down list of companies based on the first letters typed by the visitor in your “Company” field. This way you secure this crucial data for deduplication
- track the consent given by the visitor (cookie + consent by objective. Example: consent for events on a webinar registration form)

Secure ALL your data sources
These suggestions are valid regardless of the “external” input source, i.e. wherever a visitor may authenticate for the first time: marketing automation forms, webinars or events, video apps, social networks, questionnaires and self-evaluations… For example, at Merlin/Leonard, this will concern our Marketo forms, but also Outgrow (quizzes and assesments), TwentyThree (video). If one of these systems can’t provide all the preventive measures, you need to put in place security measures at the entrance to the CRM or Marketing Automation.
Secure data entry into the CRM
CRM is another source of data quality … approximately. Marketing, Sales and IT have sometimes unknowingly teamed up to put sales people in the role of scribe. This is a very bad idea. First of all, sales people’s time is worth a lot of money, and it’s a shame to ask them to do tasks that a lot of people can do, often better than them. Secondly, they have – if they are good – a personality that is the opposite of what is needed for the job of scribe. In the old days, I used to do CRM projects. I once saw an “Opportunity” page with 280 fields!

One of the best practices in terms of data quality is to audit the filling of your CRM and to remove the massively unfilled fields from the contacts, leads, opportunities pages…. When you think about it, why should there be more required fields in your CRM than in a marketing form? You agree to provide a good customer experience to your visitor by allowing them to start a relationship with you with few fields; and to complete their profile as they go along with you. Why not do the same internally with CRM users? The work you do on the marketing forms side should also apply to the CRM side:
- limit the number of fields to a maximum
- give preference to calculated, deduced and externally enriched fields
- clearly identify the fields to be entered manually, and those calculated automatically
- secure your important fields with lists of constrained values
- clearly group fields by theme (contact fields, RGPD fields, “KPIs” fields, Data Quality fields…)
Fight the Hydra as soon as it appears, or correct poor data quality on the fly
It will always happen that a head of the hydra manages to get past your best spells. Sometimes it can corrupt your own troops, who import catastrophic data and bring the evil into the kingdom themselves. How do you deal with the evil as quickly as possible once it is detected? We will focus on real-time campaigns. They will identify problems as soon as they enter, and provide an immediate solution.
Tracking data acquisition correctly
This is an eternal battle ! It’s all about being able to answer the simple questions: Where are my leads coming from? Where is my pipeline coming from? Where is my revenue coming from ? Different levels of information must be collected:
- the source: webinar, “gated” content, CRM…
- the source details: for example, for the “Webinar” source, we should have the name of the webinar
- which promotional channel brought the visitor (the famous UTMs: utm_source, utm_medium, utm_campaign)
- the date of acquisition
Quite often, without preparation, this data is at best absent, at worst inconsistent with each other. Each acquisition source must be monitored, and this information must be filled in correctly upon entry. Below is an example of a simple export of the persons in the database with the field “Person Source”. It reflects the reason that brought them into the Marketing database. We can see that many sources are spelled differently making it impossible to make a decision without reprocessing the results.

Want to know where you stand on this topic ? Follow the guide.
Correct on-the-fly lists of erroneous values
It is quite easy today with marketing automation or CRM systems to create workflows that detect that a value in a field does not correspond to the acceptable repository. For example, a team member has been corrupted and imports a file of participants to an event, but is wrong about the countries. We can analyze and find 80% of the wrong country data entered in the past. For example for United Kingdom it will be UK, U.K., Unit. King, United Kingdom, UK, UK, England… If we detect that a person entered with one of these wrong values, then immediately replace with United Kingdom. This implies to master the fields and the acceptable values. It is generally in the Data Dictionary that we will reference the “good” values for each field with a list of values.
Validate the email address
You have third-party systems that can validate an email address and avoid sending to addresses that are either :
- generic: contact@toto.com
- “personal”: sylvain@gmail.com
- traps: some email addresses are traps that, if you use them, trigger a complaint to the CNIL. It is absolutely necessary to detect and
- avoid them.
- invalid
- …
These systems allow you to avoid sending an email received and to have in return information allowing to determine the quality of the email. At Merlin/Leonard, we use CaptainVerify, on which I had made a Marketo tip.
Below is the data returned by CaptainVerify. As you can see, it’s quite rich and very useful for marketing.

Pro / Personal Email Management
Using a solution like CaptainVerify leads to having several “personal email” fields next to the standard “Email” field. We will try to keep it for the professional email. The idea is the following:
- you receive a new email
- You scan it – with CaptainVerify or by looking if the domain belongs to one of the personal email domains like Gmail.
- If not, no problem, nothing to do
- If yes, you copy it into the “Personal Email” field. Then you try to recover the professional email via a solution like DropContact.io.
- This way you will have both professional and personal email. This can be useful when the contact changes company and you receive a “Bounce” indicating that the pro email is no longer valid.
- You can then write to him on the personal email to ask him for his new personal address via the communication preferences center

Deduplicate on the fly
This is a basic feature today, fortunately. On the Marketing Automation side, your reconciliation key will be the email. Any person who enters the database via a form or an import list will normally be recognized if they already exist in the database with the same email. This allows you to enrich the customer knowledge you have of this person as you go along. On the CRM side, it is more complicated because :
- the email cannot be used as a key often enough, because there are companies where several people use the same email and you have to be able to enter them in the CRM.
- you have to imagine a functional “key” that will be used as a unique identifier when you enter people: for example Last Name + First Name + Company.
If you enter a second Sylvain Davril from M/L, the system will ask you if it is not the same as the first one.

This system is not ideal because there may be homonyms with the same name in the same company. On the other hand, these tests will also apply to everything that the marketing automation will push into the database. And sometimes reject the entry of hot leads because of a similarity. Therefore, it should be implemented if you have solved the issue of information feedback in the integration. Expert systems exist to go further and deduplicate on the basis of similarities, I talk about it below.
Take fundamental measures to prevent the Hydra of poor data quality from taking hold
We are at the edge of the Beast’s lair; it has managed to make its nest within the Kingdom. You can do something about it before it takes hold.
Synchronization between systems
A subject often overlooked but a major source of poor data quality.
>> It was better before
There was a time when integration projects included an “Error reporting and processing” component.
- Information logs were produced at each information exchange to know if the data had been exchanged correctly,
- Alerts were sent to IT and business system managers to take appropriate action
- And self-correcting measures were sometimes put in place to replay the faulty data set at a later time
>> Data quality of integrations today
Today, when we receive an alert that something has gone wrong, we consider ourselves lucky! So if there is a data transmission problem, at best, an abstruse message will be sent. The person who receives it will not be able to read it “because it is too technical”. And in any case will not have the time nor the desire to do so because there is this damn webinar to send! As a result, you can see interfaces that don’t work well for several days/weeks without anyone being concerned. And data that gets out of sync between systems.
>> Example that will speak to you:
- a person fills in your preference center and asks to exercise his right to be forgotten
- you deal with the subject on the marketing side
- an integration problem prevents data exchange with your CRM (for example, because the Country field is empty)
- a sales representative sends this person an invitation email to your next webinar
- and that’s the drama, you are summoned to the legal department, and nobody likes to be summoned to the legal department
So ask your IT department to set up these alerts, with understandable messages when a data exchange fails, so that you can act right away.

Easily identify Hydra
One way to fight the Hydra is to mobilize everyone. To do this, everyone must recognize the evil at first glance. This is the purpose of the visual indicator of Data Quality: generally a colored score, or a green/yellow/red dot on the contact form. This allows you to see immediately if an action is required or not. The indicator can be calculated according to different data on the contact form:
- field completeness: are the essential fields for the contact filled in? The number of fields required may change as the person progresses through the life cycle.
- accuracy of fields: are the fields filled in with correct data (for example, is the email valid? does the phone number look like a real number? Are the values in the value list fields correct?)
- freshness of data: is the data recent?
Inferring data from other data
In the spirit of reducing data entry requests for both visitors and sales, you can now automate data deduction.
Example 1: Civility
For example, the civility can be deduced in part from the first names.
- If First Name = Mary or Claire or … then the civility is “Mrs”.
- If First name = Jeau or Paul or … then the civility is ” Mr “.
There is a list of first names whose civility is “safe” by country. It is then quite easy to create this type of cross-functional Data Quality campaign.
Example 2: The decision-maker level
Similarly, from the “position”, we can often deduce the decision-maker level.
- If the position contains Director, DG, CEO, Partner… then the decision maker level is “Decision maker
- If the position contains student, consultant, journalist, freelance, then the decision level is “Other
- Otherwise, the decision level is “Middle management”.
And so on for example for the Person Service again from the Position.

Data Enrichment
One level above, data enrichment requires the use of a third party database. It is up to you to decide when you call this database to enrich the data:
- at the creation of the contact in your database, which allows you to have “clean” records as input; and afterwards continue the other Data Quality processes, for example deduplication; this method nevertheless risks generating many calls
- at a certain point in the customer journey, for example, just before passing it on to sales. This reduces the number of calls and the cost. And it comes at a crucial time, reducing the qualification work of the sales team.
We use Dropcontact.io at Merlin/Leonard. Here is the type of data we can retrieve from a first and last name and an email

There are several ways to integrate this data into your database: You can directly overwrite existing fields with the imported data. Or you can create dedicated fields to store the imported data, and save fields to keep track of the data you are going to overwrite. You save the data before overwriting it.
The Hydra is here: putting together a team to bring the monster out of its lair
Communication Preference Center
We have quite a bit of literature on the preference center and GDPR. Without a preference center, there is no collection of fine-grained consent from your visitors, and therefore no successful customer experience. Your customers may want to be informed about your events and expertise documents, but they don’t want to read your newsletter or product promotions. I quite often meet clients who have not really managed the subject of “Consent” – well less and less – and where the documentation is non-existent. There are mixtures of “opt-out” and “opt-in” fields at the global level – include/exclude from everything – and at the local level – include/exclude from the newsletter for example -. When you start to analyze the data, you find people with opt-in consents on the newsletter for example who are also opt-out at the global level. The result is that it is difficult for them to know how to include or exclude people in the base when they create a campaign. And this leads to complaints from customers who have asked to be excluded and are still receiving communications, or conversely, from people who have asked to be included but you are not reaching them. This is not possible. The consent to choose must be obvious from the campaigns. Put yourself in the place of the person who has not designed the fields to be chosen, who hesitates, who is afraid of making a mistake… The solution is to set up a preference center, where all these management rules are properly managed.
Regular data enrichment
On average, 15% of the base changes positions every year. It is good to enrich the data at the entrance, it is even better to plan this regularly. How to do this? With modern marketing automation systems, nothing could be easier. For example, you can set up a rule saying that you will make a call to the third party enrichment database:
- as soon as the person’s behavioral score changes (this means they are active)
- but limit calls to one every 6 months or a year
KPIs and Data Quality Reports
It’s usually a huge time saver when you have your report sets and dashboards ready to go. You can send them to yourself every week to keep an eye on the status of the base. In truth, this hardly ever happens 😉 This is an effort to make as you go about your various Data Quality projects. In my opinion, the ideal Data Quality report pack contains – on the CRM and/or Marketing automation side – the data to answer the questions below:
- Data acquisition: are the sources correct? are the sources consistent with the source campaigns? Do all people have a source and an acquisition campaign?
- Preference center: are the consent data correct? (if you put lists of Yes/No values, are there only these two values and “NULL”?) Are the local and global consents consistent (person in global optout and optin = Yes on the newsletter). Are the dates of consent changes well traced?
- Value Lists: Do value list fields contain only acceptable values?
- Scoring / Lead Life cycle: Do all people have a status corresponding to their place in the Lead Life Cycle? Are the statuses and the score consistent? Are some people stuck on a status for a suspiciously long time?
These reports should allow you to quickly identify the problem, and the source of the evil. It’s up to you to correct it. A small example of a series of Marketo Smart Lists oriented Data Quality around the Lead Life Cycle

Massive deduplication
We are talking about identifying and solving the following types of situations:
- identify + correct that two people with the same email and slightly different names are the same:
- Sylvain Davril sylvain.davril@merlinleonard.com
- and Silvain D’avril sylvain.davril@merlinleonard.com
- identify + correct that two people with identical attributes but different emails are the same:
- Sylvain Davril sylvain.davril@merlinleonard.com
- Sylvain Davril sylvain.davril@gmail.com
- identify that two (or more) people with slightly different attributes and emails are the same
- Sylvain Davril from Merlin/Leonard
- Silvain D’aville from Merlin
Expert systems like Cloudingo can calculate a similarity score based on strings of characters – here first name+last name+company -. And tell you if the string is “similar” or not (for techy, it’s based on the Jaro-Winkler score). It’s up to you to decide to merge or not, manually or automatically.
Generally, a first pass of massive deduplication is done when the solution is installed; then we operate by detection as the contacts enter the base.